Jeremy Stanley

I am the co-founder and Chief Scientist of Anomalo, an AI platform that helps enterprises monitor and improve data quality. Before founding Anomalo, I was VP of Data Science at Instacart, where I led machine learning efforts and drove key initiatives toward profitability and sustainable growth.
I’m currently taking a career break and spending my time exercising, reading, researching, and exploring. I’ve collected my past writing and favorite books on this site.
Stay tuned for new essays I write by subscribing on Substack.
Writing
My writing on Anomalo, Instacart and other topics.

Stepping Back
Announcing my decision to step back from an operating role at Anomalo due to health changes. Reflects on my career through the lens of proving a well known VC wrong - both about making Instacart profitable and about creating Anomalo.

Automating Data Quality (O’Reilly)
A practical guide to building and maintaining automated data quality monitoring systems that scale across cloud data platforms. It explains how to design and test unsupervised learning models for issue detection, implement effective alerting and resolution workflows, and manage these systems enterprise wide.

An All-In Founder Forum
Recounts the origin and structure of a peer forum of venture-backed founders focused on vulnerability, accountability, and personal growth. Shares operating norms, meeting cadence, and an open invite for a new member.
Build Data Factories, Not Data Warehouses
Modern organizations operate data factories (not warehouses) that transform raw inputs into dynamic, customized data products. To ensure these factories produce trustworthy outputs, data teams must invest in scalable, automated quality control systems that empower data consumers, minimize false alerts, and validate data at every stage, especially before delivery.

Detecting Extreme Data Events
Introduces Anomalo’s entity outlier check to catch rare, high-impact events by pairing time-series anomaly detection with automated root-cause analysis. Demonstrates the approach with NYC 311 data and contrasts it with generic outlier methods that fail in real-world settings.
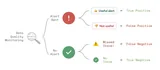
Effective Data Monitoring: Steps to Minimize False Alerts
Offers ten actionable steps to reduce false positives and negatives in data monitoring systems and to calibrate alerting thresholds. It guides teams in balancing sensitivity and signal-to-noise to maintain trust in monitoring systems.

Trust Your Data with Unsupervised Data Monitoring
Presents how unsupervised learning can detect unexpected anomalies in data without requiring labeled incidents. It shows how combining forecasting with unsupervised signals helps improve coverage over simple rules-based monitoring.
Airbnb Quality Data For All
Airbnb’s growth demanded strong automated systems to keep its data complete, timely, and reliable. The article shows how companies can achieve similar data quality using tools like Anomalo without massive budgets.

Dynamic Data Testing
Defines a framework from static rules to dynamic, model-based tests and unsupervised detection for higher coverage with less maintenance. Uses EU COVID-19 data to show how predicted ranges outperform hand-tuned thresholds and avoid missed anomalies.

When Data Disappears
Explains why missing or partially missing data is the most common—and dangerous—data quality failure, often invisible in aggregate metrics. Outlines practical tests to detect staleness, shortfalls, and segment drop-offs, with alerting workflows for rapid triage.

700 Women Founders
Analyzes 2009–2013 Crunchbase data to estimate the share of venture-backed companies with women founders and ranks VC portfolios by representation. Argues for transparency and accountability by using data to surface diversity gaps in venture funding.
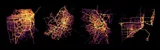
Space, Time and Groceries
Frames Instacart grocery delivery as a spatiotemporal logistics problem and describes the architecture used to optimize it. Uses Datashader to visualize massive Instacart GPS datasets that reveal how shoppers move through cities, stores, and delivery routes.

How Instacart Uses Data to Craft A Bespoke Comp Strategy
Details Instacart’s compensation methodology combining survey data and regression modeling, mapped to precise leveling to ensure fairness and competitiveness. Shares outcomes and tactics for market positioning, equity education, and calibration across roles and seniority.

3 Million Instacart Orders, Open Sourced
Instacart released an anonymized public dataset of over 3 million grocery orders from more than 200,000 users to support machine learning research on consumer purchasing behavior. The article introduces the dataset, highlights privacy protections, and shares some initial insights from the data.
Deep Learning with Emojis (not Math)
Offers an intuition-first explanation of deep learning concepts (using emojis) aimed at non-technical readers, connected to Instacart’s efforts in ranking and route optimization for shopping in store. It frames how deep learning ideas can be communicated without math-heavy exposition.

Doing Data Science Right — Your Most Common Questions Answered
Provides concise, high-leverage answers to recurring challenges in building and scaling data science teams, from scope setting to stakeholder alignment. It distills practical wisdom from leaders across many companies into a Q&A format.

Data Science at Instacart
How the data science organization at Instacart works in partnership with product and engineering to drive key decisions and outcomes. Outlines the data opportunities in forecasting, ads, recommendations, and search optimization.

How to Consistently Hire Remarkable Data Scientists
Describes a structured approach to recruiting, evaluating, calibrating, and retaining exceptional data science talent, with emphasis on projects that reflect real work. It highlights how to design take-homes and interviewing loops that predict long-term success.
Reading
Favorite books that have influenced my thinking.
The Scaling Era: An Oral History of AI, 2019-2025
As a recent follower, I was excited to read The Scaling Era, which organizes excerpts from his conversations leading up to 2025 in a single place. Dwarkesh, in text form, has a real advantage. The material is laid out topically, moving from scaling and evals through safety, impact, and the possibility of an explosion. Reading it gave me time to pause on assertions, research the individuals making them, and, of course, debate with AI along the way.
The tradeoff is that conversational context is lost. You don’t get a strong feel for the people he’s speaking with or their broader perspectives. I want to return to a handful of key interviews from this period and listen to them uninterrupted.
I enjoyed guests speculating about the very near future the most, largely because we are now there and can validate it against reality. Much rang true, perhaps because many of these ideas were already known at the frontier well in advance of filtering to the rest of us. Only time will tell whether the more distant predictions hold up.
I loved reading this book. It filled in many nuanced gaps in my understanding of the current state of the art and how we arrived here. The physical book itself is also beautifully produced, with clear typography, thoughtful margin definitions, a subtle progress bar, elegant footnotes, and visualizations that genuinely add context. I don’t usually praise such things, but in this book, they really mattered.
I hope that someday soon, Dwarkesh publishes a sequel to his book, titled "The Singularity Era: An Oral History of AGI, 2026-????". I'll be waiting.

The MANIAC
A portrait of Von Neumann’s life, seen through fictionalized letters written by his family, friends, and colleagues. Framed by a tragic account of the theoretical physicist Paul Ehrenfrest, and the dramatic Go matches between Lee Sedol and AlphaZero. Labatut draws connections between madness, power, intelligence and AI that are powerful, if at times naive or contrived. The result is an awe-inspiring impression of Von Neumann’s brilliance and his uncanny foresight into the future of computing and AI at the dawn of the digital age.

Pieces of the Action
Vannevar was FDR's science advisor during WWII, and shepherded tech from penicillin to proximity fuses to the atomic bomb. His advice on aligning scientists with the hierarchical war effort applies to any tech org. The challenges he saw the US facing in the 1970s, compared to the progress we have made and what we face today, is heartening. His vision for the future of personal computing (the Memex) was prophetic if incomplete. Written in 1970 and republished in 2022, it could have used a firmer edit, but Bush's voice and anecdotes shine through. I gained an entirely new perspective on innovation and its messy deployment in practice.

Causal Inference in Python: Applying Causal Inference in the Tech Industry
Teasing causality from data is one of the most subjective and challenging tasks that data scientists face. This book provides a thoughtful, fun to read, and practical introduction to causal inference. It covers a lot of ground, from causal graphs to synthetic controls to ML estimates for user level treatment effects. By weaving together theory and code, Facure turns what’s often an abstract topic into something directly usable in industry settings. The math notation is not always clear, but the code examples and reasoning are fantastic. Much of what's here I had to figure out over the course of my career. Other ideas were entirely new to me - and I can't wait to apply them.

Abundance: What It Takes to Build
I found this book to be timely and exciting, as it is written by respected journalists from the left and clearly diagnoses the failures to support the supply side required for achieving Abundance as a society. They convincingly argue that homelessness stems from a simple fact: we don’t build enough housing. They identify many of the factors crippling our ability to build in liberal cities. They illustrate how well-meaning special interests on the left can cripple legislation like the CHIPS act. They explain the history of legal tools created to fight abuse of the commons in the 60s and then explain how those same tools are now used by all to obstruct progress. They critique our federal science apparatus for being too risk averse and bureaucratic. I didn't leave the book with a clear blueprint for what should come next, but I hope this book inspires the start of one.

The Alchemy of Air
We could have all starved, and by the end of the 19th century, that was the prevailing belief. But then we mastered turning air and fuel into fertilizer. Hager begins with the limits of organic farming and a world reliant on a few remote deposits of guano and nitrates before guiding us into the modern era of synthetic fertilizer. He builds fascinating portraits of Haber, the scientist who solved the chemistry, and Bosch, the industrialist who scaled it. Both were brilliant, deeply troubled men who became entangled in Nazi Germany. The book weaves an engrossing tale of how scientific discovery and complex engineering went hand in hand, and how our salvation from starvation also laid the groundwork for two world wars.

The New World on Mars: What We Can Create on the Red Planet

Chip War: The Fight for the World's Most Critical Technology

Structures: Or Why Things Don't Fall Down

The Lessons of History

Numbers Don’t Lie: 71 Stories to Help Us Understand the Modern World

Other Minds: The Octopus, the Sea, and the Deep Origins of Consciousness

The Beginning of Infinity

The Almanack of Naval Ravikant: A Guide to Wealth and Happiness

The Rational Optimist: How Prosperity Evolves

Factfulness: Ten Reasons We’re Wrong About the World—and Why Things Are Better Than You Think

Einstein: His Life and Universe

Thinking, Fast and Slow

Benjamin Franklin: An American Life

Why We Sleep: Unlocking the Power of Sleep and Dreams

The Red Queen: Sex and the Evolution of Human Nature

Deep Learning


Sapiens: A Brief History of Humankind

An Introduction to Statistical Learning (2nd ed.)

The Goal: A Process of Ongoing Improvement (40th Anniversary Edition)

The Elements of Statistical Learning

The Botany of Desire: A Plant’s-Eye View of the World

The Visual Display of Quantitative Information (2nd ed.)

Neural Networks for Pattern Recognition

My Brain is Open: The Mathematical Journeys of Paul Erdős

How to Avoid a Climate Disaster

High Output Management

High Growth Handbook

Steve Jobs

The Phoenix Project

ggplot2: Elegant Graphics for Data Analysis (Use R)

Modern Applied Statistics with S (Statistics and Computing)

Advanced R (Chapman & Hall/CRC The R Series)


Fluent Python

Deep Learning with Python

The Wisdom of Life and Counsels and Maxims



A Promised Land

Genghis Khan and the Making of the Modern World

Endurance: Shackleton's Incredible Voyage

Buried in the Sky: The Extraordinary Story of the Sherpa Climbers on K2's Deadliest Day

Alone on the Ice: The Greatest Survival Story in the History of Exploration

The Art of Learning: A Journey in the Pursuit of Excellence
